Bunka Explore
Interactive topic modeling and visualization platform
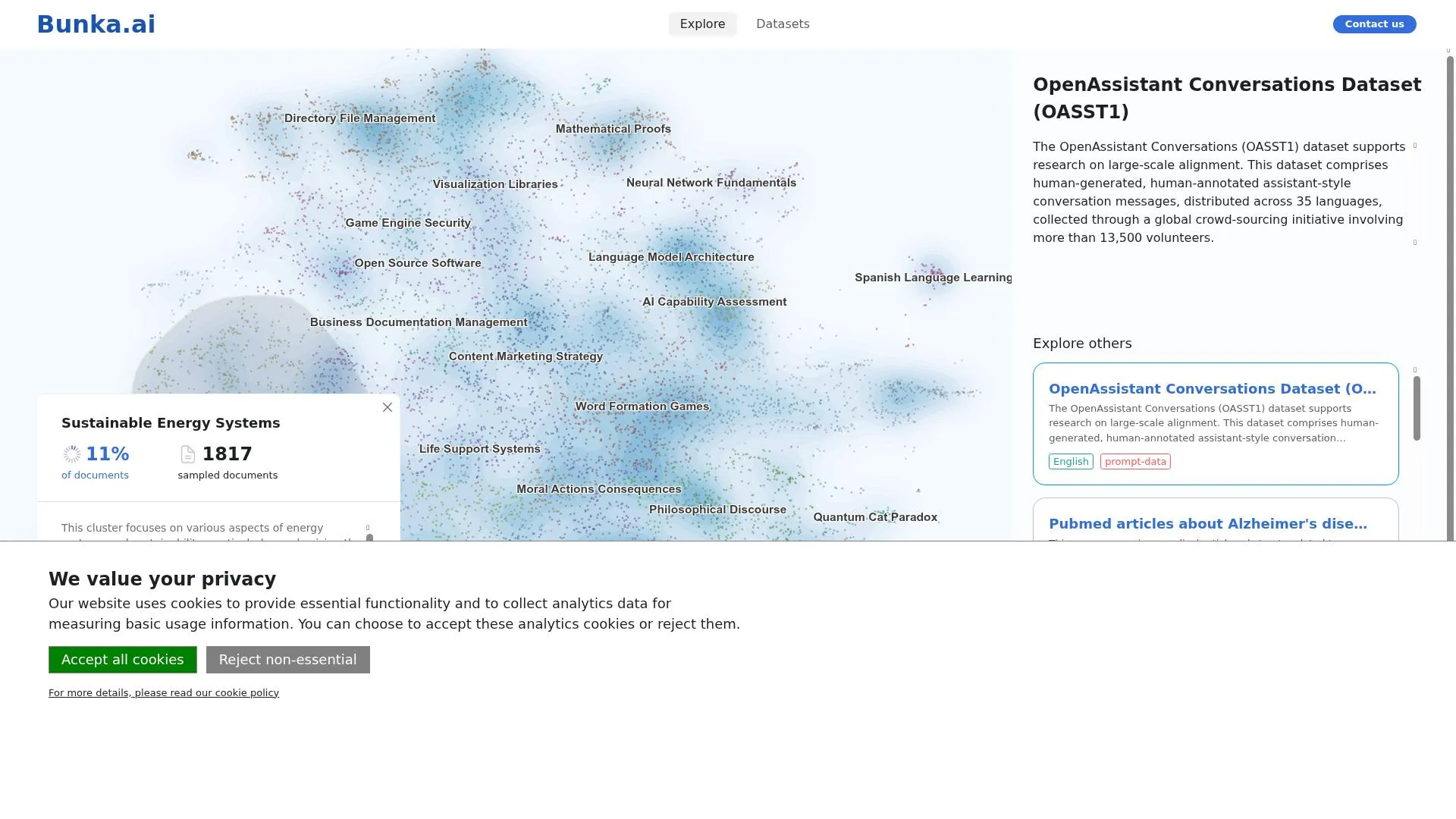
Overview
Bunka Explore is a topic modeling and visualization platform that transforms large textual datasets into interactive 2D maps. Built by Bunka.ai, it addresses the growing challenge of extracting meaningful insights from overwhelming volumes of text — whether from AI-human conversations, social media, news articles, or AI training datasets. Users upload CSV datasets, and the platform runs NLP topic modeling to produce interactive scatter plots where related topics appear as clusters, thematic relationships become visible through proximity, and unexpected patterns emerge organically from the data. The platform was developed with collaborative support from CNRS, the PRAIRIE Institute, the French Ministry of Culture, PSL University, and Ecole Normale Superieure.
Tech Stack
Technical Details
The frontend is a React 18 SPA built with TypeScript and Vite, using Radix UI for the component library. The core visualization engine is built entirely with D3.js — rendering interactive scatter plots of document embeddings with topographic contour density backgrounds, convex hull cluster boundaries, and smart non-overlapping label placement. A quadtree data structure provides O(log n) nearest-neighbor lookups for hover interactions across up to 10,000 documents.
The backend architecture separates concerns cleanly: Supabase handles all CRUD operations, authentication, file storage, and real-time progress subscriptions via Postgres change events. Heavy NLP computation — topic modeling, embeddings, and clustering — runs on a dedicated Python compute server. Users select from multiple embedding models including MiniLM, UAE-Large, and multilingual-e5, supporting analysis across languages.
The data pipeline flows from client-side CSV parsing (PapaParser) through Supabase Storage, to the compute backend for processing, with real-time progress updates streamed back to the UI. The app deploys as static files via GitHub Actions to Scaleway S3, with Nginx handling routing, gzip compression, and reverse proxying to the compute backend with extended timeouts for long-running NLP jobs.